自注意力机制
Self-Attention Mechanism
自注意力机制是Transformer架构的核心,也是现代深度学习在处理序列数据方面取得突破的关键。它允许模型在处理序列中的一个元素时,能够同时权衡和考虑序列中所有其他元素对它的重要性,从而捕捉到长距离依赖关系,并实现高效的并行计算。
核心思想:全局依赖与动态权重
传统的RNN通过循环结构处理序列,难以捕捉长距离依赖。CNN通过局部感受野处理局部信息。自注意力机制则完全不同,它为序列中的每个元素动态地计算一个权重,表示序列中其他元素对当前元素的重要性。
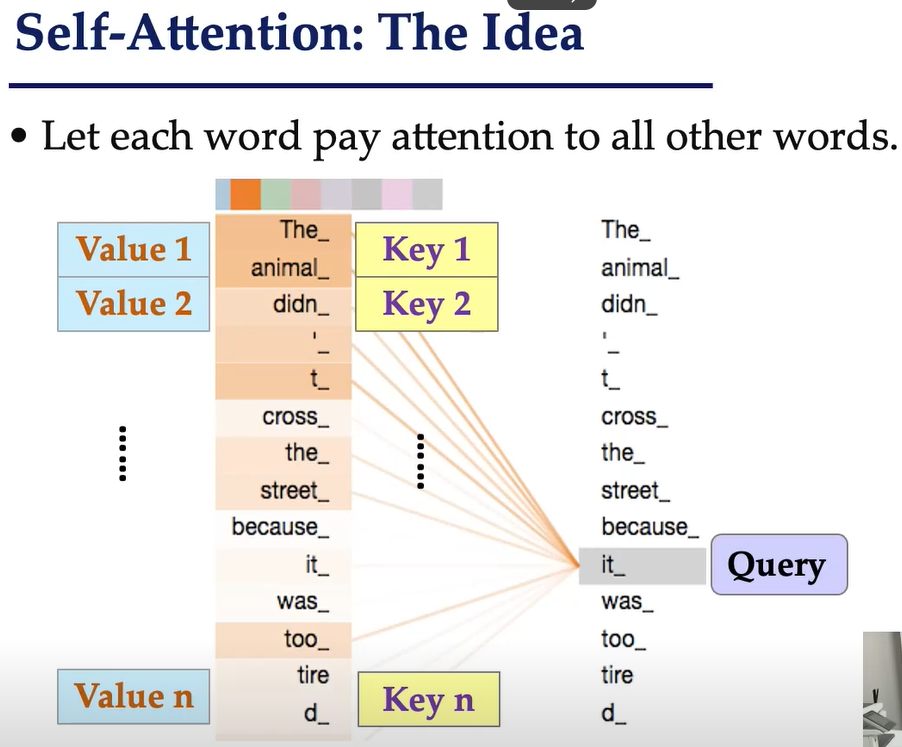
想象一句话:“The animal didn't cross the street because it was too tired.” 当模型处理“it”这个词时,自注意力机制会计算“it”与这句话中所有其他词(包括“animal”、“street”、“tired”等)之间的相关性,并根据相关性分配不同的权重,从而帮助模型理解“it”指的是“animal”。
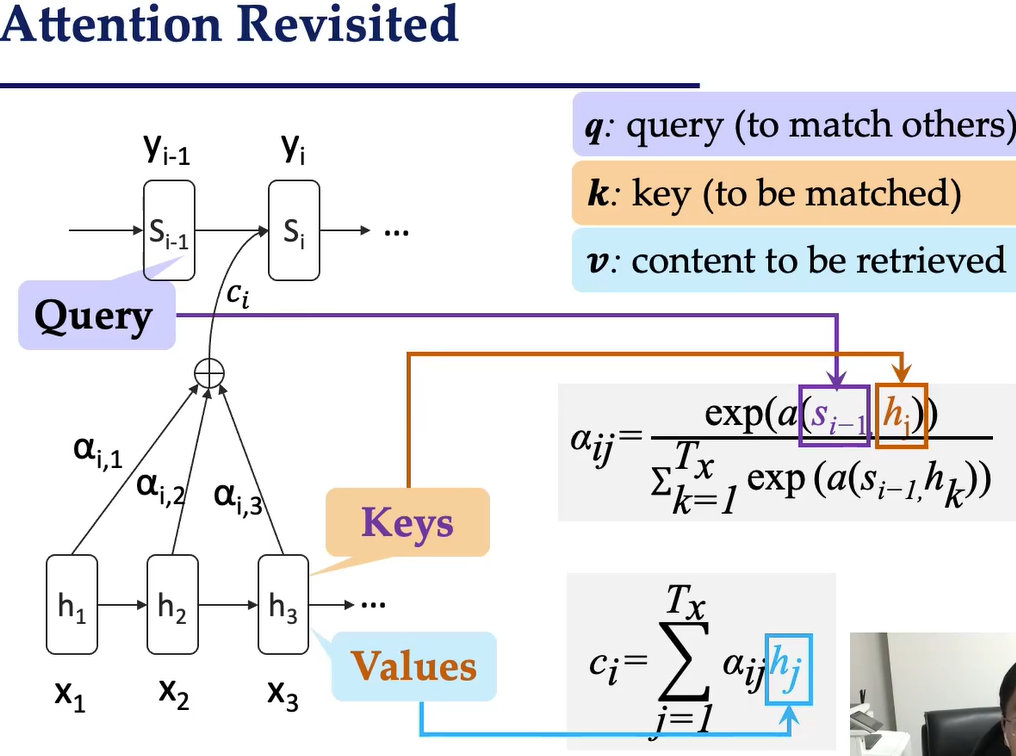
QKV模型:查询、键、值
自注意力机制的计算基于三个核心概念:
- 查询 (Query, Q): 代表当前正在处理的元素(或词)的信息。它用来“查询”序列中的其他元素。
- 键 (Key, K): 代表序列中所有其他元素的信息。它们用来与“查询”进行匹配。
- 值 (Value, V): 代表序列中所有其他元素的内容信息。当“查询”与某个“键”匹配成功后,对应的“值”就会被提取出来。
对于输入序列中的每个元素,都会生成一个Q向量、一个K向量和一个V向量。这些向量通常是通过将原始输入嵌入向量与三个不同的权重矩阵相乘得到的。
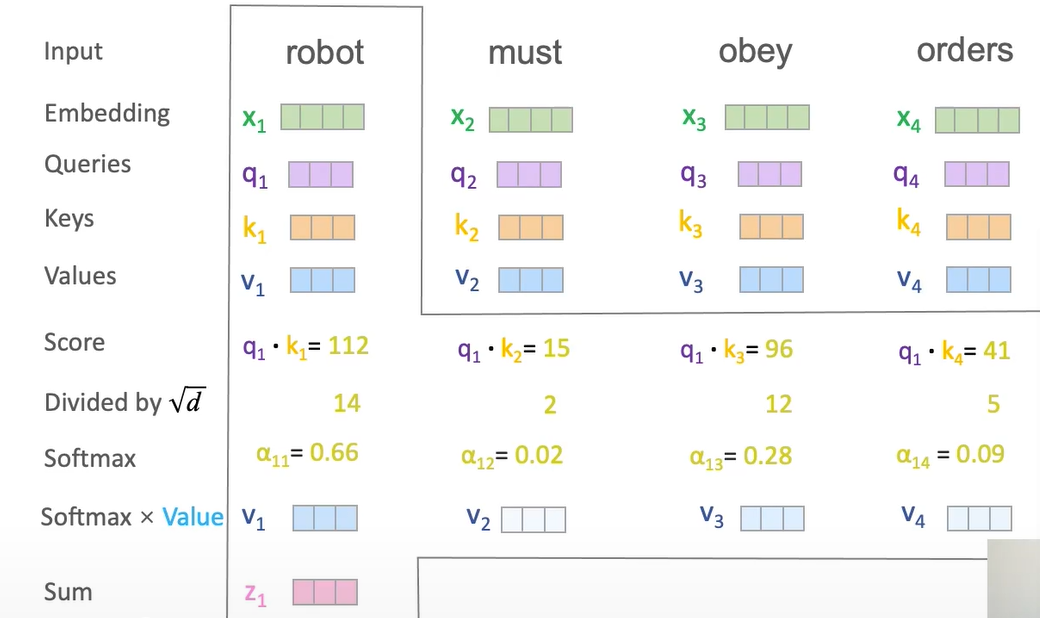
计算过程:Scaled Dot-Product Attention
自注意力机制最常用的形式是缩放点积注意力 (Scaled Dot-Product Attention)。其计算过程如下:
- 计算注意力分数: 将Query向量
与所有Key向量 进行点积运算。这衡量了每个Key与Query的相似度或相关性。 - 缩放 (Scaling): 将点积结果除以
进行缩放,其中 是Key向量的维度。这有助于防止点积结果过大,导致Softmax函数进入梯度饱和区。 - Softmax: 对缩放后的结果应用Softmax函数,将分数转换为权重,确保所有权重的和为1。这些权重表示了序列中每个元素对当前Query的关注程度。
- 加权求和: 将Softmax得到的权重与Value向量
进行加权求和。最终得到的结果就是当前元素融合了全局上下文信息的新表示。
多头注意力 (Multi-Head Attention)
为了让模型能够从不同角度、在不同表示子空间中关注信息,Transformer引入了多头注意力。它不是只进行一次自注意力计算,而是并行地运行多个独立的自注意力“头”。
- 工作方式: 将Q、K、V矩阵分别线性投影到多个不同的子空间,然后每个子空间独立地进行自注意力计算。最后,将所有“头”的输出拼接起来,再进行一次线性变换,得到最终结果。
- 优点: 允许模型同时关注来自不同位置的不同类型信息,增强了模型的表达能力和鲁棒性。
优势与影响
- 并行计算: 自注意力机制的计算不依赖于序列的顺序,可以高度并行化,极大地加速了训练过程。
- 长距离依赖捕捉: 任意两个位置之间的依赖关系都可以在一步计算内直接建立,解决了RNN的长程依赖问题。
- 可解释性: 注意力权重可以直观地显示模型在做决策时“关注”了序列中的哪些部分。
自注意力机制的提出,彻底改变了自然语言处理领域,并被成功地扩展到计算机视觉等其他领域,成为现代深度学习模型(尤其是大语言模型)的核心。
历史
自注意力机制
并行
注意力机制:
信息查找
query 查询
Token Embedding
将单词转为词向量
Q, K, V vectors
每个单词充当三种角色
词向量经过线性变换(乘以矩阵)
转为三个向量
- query
- key
- value
计算注意力的分值
attention scores for each <query,key> 内积
利用 softmax 将分数转化为概率
aggregate values based on Attention weights
更新词向量的状态
并行操作
- H 词向量矩阵
- Q, K, V 线性变换得到的三个矩阵
- H' 更新后的词向量矩阵
GPU 加速,并行计算
保留词的顺序
直接将单词的顺序输入
位置向量