Transformer
Transformer
Seq2seq model with Self-attention
Transformer是一种基于自注意力机制Self-attention 的深度学习模型框架,最早用于处理序列数据,尤其在自然语言处理(NLP)中取得了突破性成果,如今也广泛应用于计算机视觉、语音处理等领域。
与传统的递归神经网络(RNN)、卷积神经网络(CNN)不同,Transformer完全基于注意力机制,摒弃了序列依赖和局部卷积,能够并行处理整个输入序列。
Transformer 已成为现代自然语言处理(NLP)领域的绝对基石,是几乎所有大语言模型(如 GPT 和 BERT)的核心。
提出背景
在Transformer出现之前,序列建模主要靠:
- RNN/LSTM/GRU:逐步读取输入,难以并行,难以捕捉长距离依赖。
- CNN变种:虽然可以并行,但对长距离依赖建模能力仍有限。
这些方法存在的核心问题:
- 训练慢:因为序列依赖,难以批量并行。
- 捕捉长依赖难:信息在长序列上传递容易衰减。
于是,Vaswani等人(Google Brain)在2017年提出Transformer(论文《Attention is All You Need》),用自注意力机制完全替代RNN和CNN,极大地提升了训练效率和效果。
核心机制:自注意力机制 (Self-Attention)
自注意力是 Transformer 的灵魂。它允许模型在处理序列中的一个元素(如一个词)时,能够同时权衡和考虑序列中所有其他元素对它的重要性。
QKV 模型: 自注意力的计算过程可以被抽象为对“Query(查询)”、“Key(键)”和“Value(值)”的操作。
- 对于输入序列中的每个词,都创建三个不同的向量:Query 向量(
)、Key 向量( )和 Value 向量( )。 - 要计算一个词的表示,我们用它的
向量去和所有其他词的 向量进行点积运算,得到一个注意力分数 (Attention Score)。这个分数衡量了“查询”与各个“键”的匹配程度。 - 将这些分数通过一个 Softmax 函数进行归一化,得到一组权重。
- 将这些权重分别与每个词对应的
向量相乘,然后加权求和。结果就是该词经过自注意力计算后得到的、融合了全局上下文信息的新表示。
- 全局依赖捕捉: 任意两个位置之间的依赖关系都可以在一步计算内直接建立,路径长度为 O (1)。
- 高度并行化: 对序列中每个元素的计算都可以独立进行,极大地提升了训练效率。
基本原理
核心思想总结为一句话:
让每个位置的元素根据输入序列中所有其他位置的信息自适应地建模依赖关系。
靠什么做到?
- 自注意力(Self-Attention)
- 多头注意力(Multi-Head Attention)
- 残差连接(Residual Connection)
- 层归一化(Layer Normalization)
- 前馈网络(Feed Forward Network)
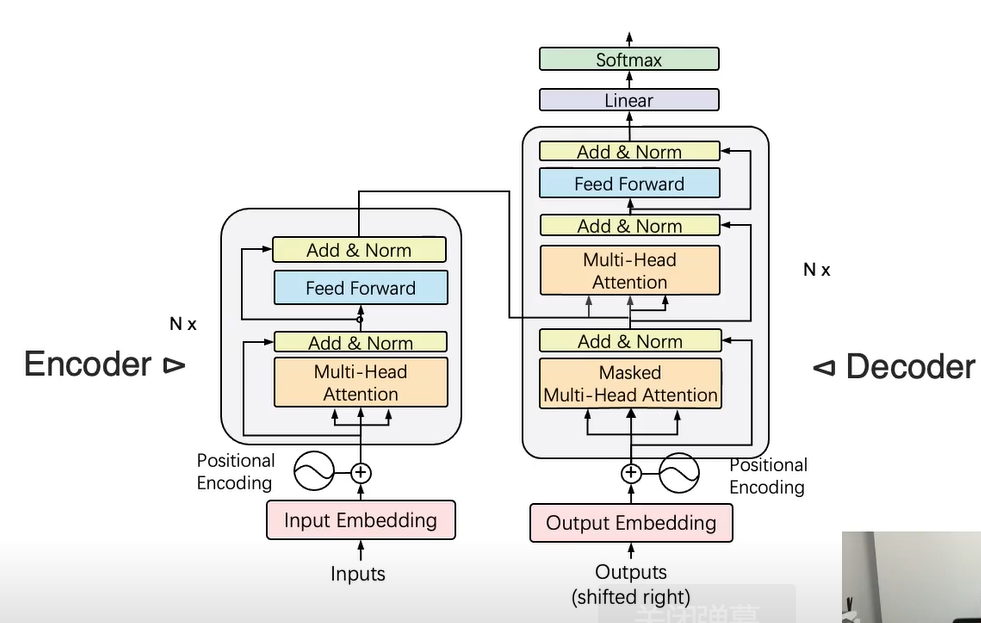
核心架构
标准的Transformer模型分为两大部分:
每个Encoder和Decoder都是堆叠多个层(Layer)**组成的。
| 模块 | 作用 |
|---|---|
| Encoder(编码器) | 输入处理,提取上下文信息 |
| Decoder(解码器) | 生成输出,常用于翻译、文本生成等任务 |
架构组成
原始的 Transformer 模型采用了一个编码器-解码器 (Encoder-Decoder) 的结构,主要用于机器翻译任务。
- 编码器 (Encoder): 由 N 个相同的层堆叠而成。每一层主要包含两个子层:一个多头自注意力层 (Multi-Head Self-Attention) 和一个简单的位置前馈网络 (Position-wise Feed-Forward Network)。每个子层后面都跟着一个残差连接和层归一化。
- 解码器 (Decoder): 结构与编码器类似,但其多头注意力部分包含两种注意力:一种是自身的“掩码多头自注意力”(确保在预测当前词时不会看到未来的词),另一种是“交叉注意力”(Cross-Attention),它接收编码器的输出,帮助解码器关注输入序列中的相关部分。
Encoder
每个Encoder Layer包含:
- 多头自注意力子层(Multi-Head Self Attention)
- 前馈全连接子层(Feed Forward Network)
- 加残差连接和层归一化(Residual + LayerNorm)
Decoder
每个Decoder Layer包含:
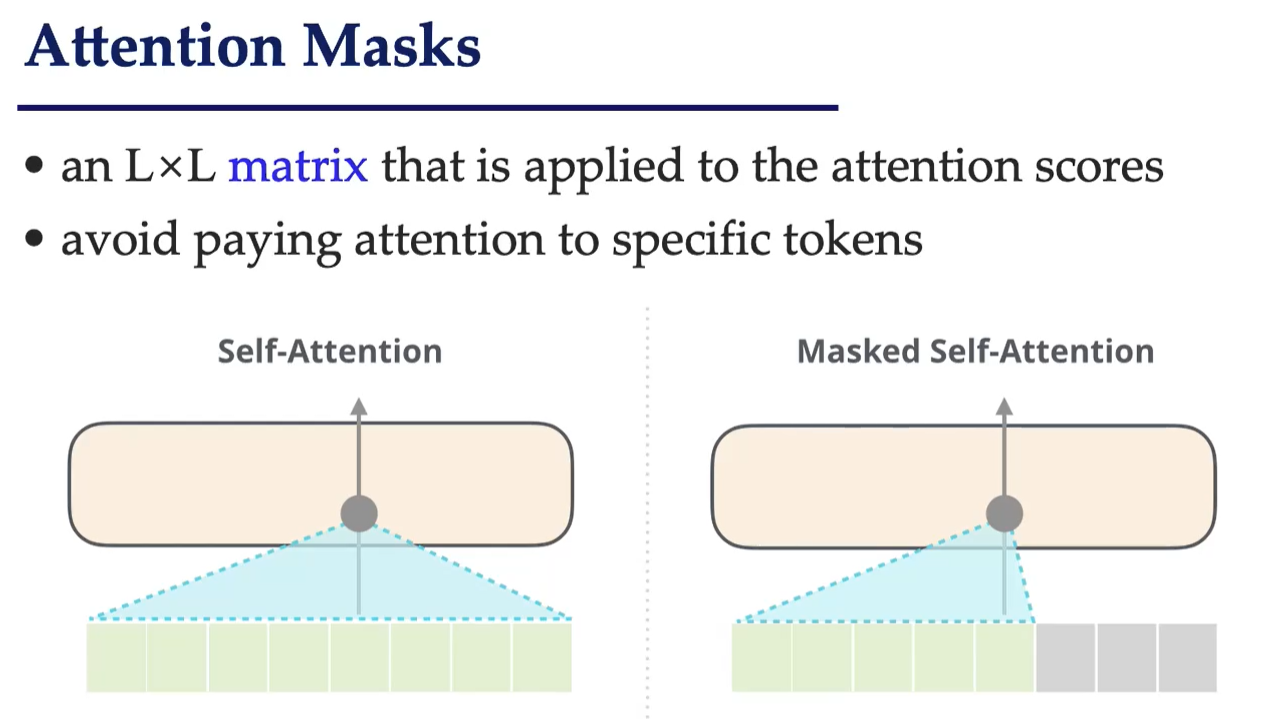
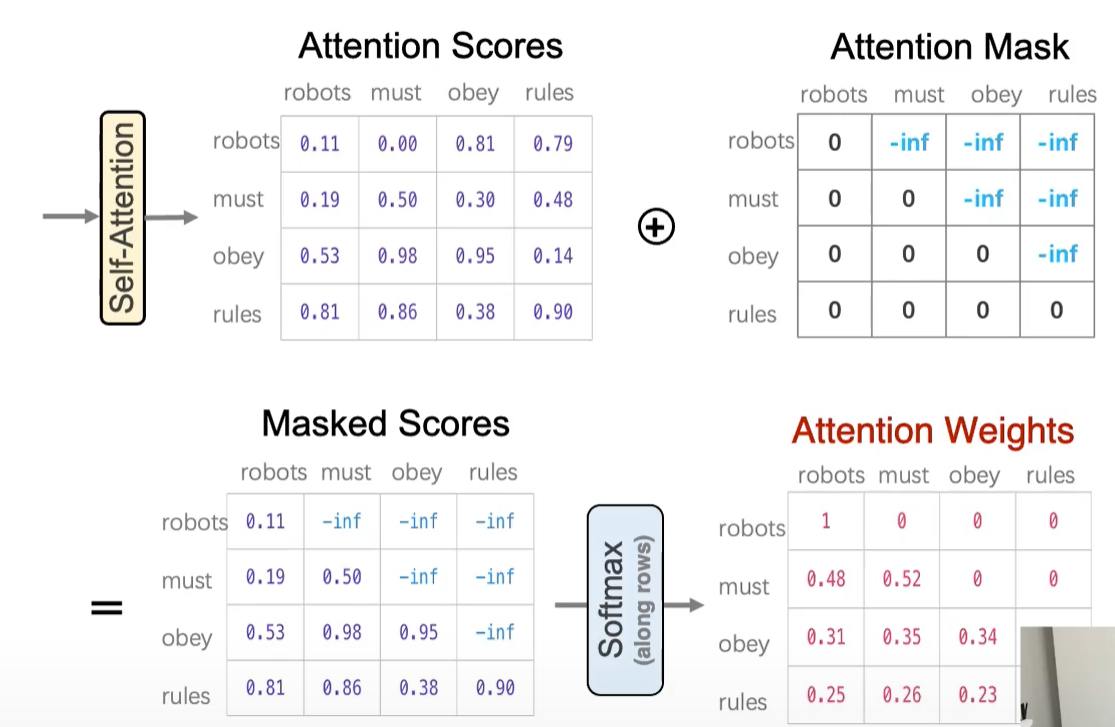
- Masked 多头自注意力子层(防止看到未来的输出)
- 多头注意力(对Encoder输出进行Attention)
- 前馈全连接子层
- 残差连接和层归一化
关键机制
自注意力(Self-Attention)
让序列中的每一个元素都对其它所有元素进行加权求和,从而动态建模它与其它元素的依赖关系。
(Query), (Key), (Value)是输入经过线性变换得到的 是Key向量的维度,用来缩放 - softmax用于归一化权重
每个词或图像Patch都能动态关注其他位置的重要信息
多头注意力(Multi-Head Attention)
不同头可以关注不同层次、不同角度的信息(局部、全局、不同语义特征)
- 将输入分成多个子空间(头)
- 各自独立做注意力计算
- 最后再拼接(Concat)起来
这大大提高了模型的表达能力!
残差连接 + 层归一化(Residual + LayerNorm)
- 残差连接(Skip Connection):缓解梯度消失,使深层网络更容易训练。
- 层归一化(Layer Normalization):稳定训练,加速收敛。
每一个子层(Attention、Feed Forward)后面都会加这两步。
位置编码(Positional Encoding)
由于Transformer完全放弃了RNN的顺序性,需要显式告诉模型"顺序信息"。这样模型就能利用不同频率编码位置信息。
| 模型 | 特点 | 应用领域 |
|---|---|---|
| BERT | Encoder部分,预训练-微调范式 | 自然语言理解(NLU) |
| GPT系列 | Decoder部分,生成式预训练模型 | 文本生成(NLG) |
| Vision Transformer(ViT) | 直接把图像切成Patch后用Transformer处理 | 图像分类 |
| DETR | Transformer用于目标检测 | 计算机视觉 |
| Speech-Transformer | 语音识别与理解 | 语音处理 |
发展方向
- 更高效的注意力机制(比如Linformer、Performer,降低到线性复杂度)
- 跨模态Transformer(统一文本、图像、声音处理)
- 微调优化(如LoRA、Adapter、Prompt-tuning)
- 长序列处理能力增强(如Longformer、BigBird)