Basic-Concepts
This chapter introduces the basic concepts of reinforcement learning. These concepts are important because they will be widely used in this book. We first introduce these concepts using examples and then formalize them in the framework of Markov decision processes.
1.1 A grid world example
Consider an example as shown in Figure 1.2, where a robot moves in a grid world. The robot, called agent, can move across adjacent cells in the grid. At each time step, it can only occupy a single cell. The white cells are accessible for entry, and the orange cells are forbidden. There is a target cell that the robot would like to reach. We will use such grid world examples throughout this book since they are intuitive for illustrating new concepts and algorithms.
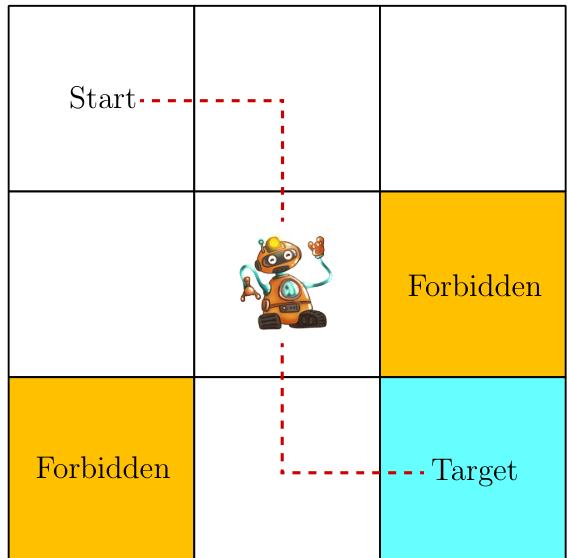
Figure 1.2: The grid world example is used throughout the book.
The ultimate goal of the agent is to find a "good" policy that enables it to reach the target cell when starting from any initial cell. How can the "goodness" of a policy be defined? The idea is that the agent should reach the target without entering any forbidden cells, taking unnecessary detours, or colliding with the boundary of the grid.
It would be trivial to plan a path to reach the target cell if the agent knew the map of the grid world. The task becomes nontrivial if the agent does not know any information about the environment in advance. Then, the agent must interact with the environment to find a good policy by trial and error. To do that, the concepts presented in the rest of the chapter are necessary.
1.2 State and action
The first concept to be introduced is the state 状态, which describes the agent's status with respect to the environment.
In the grid world example, the state corresponds to the agent's location. Since there are nine cells, there are nine states as well. They are indexed as
状态空间:The set of all the states is called the state space, denoted as
For each state, the agent can take five possible actions: moving upward, moving rightward, moving downward, moving leftward, and staying still. These five actions are denoted as
The set of all actions is called the action space, denoted as
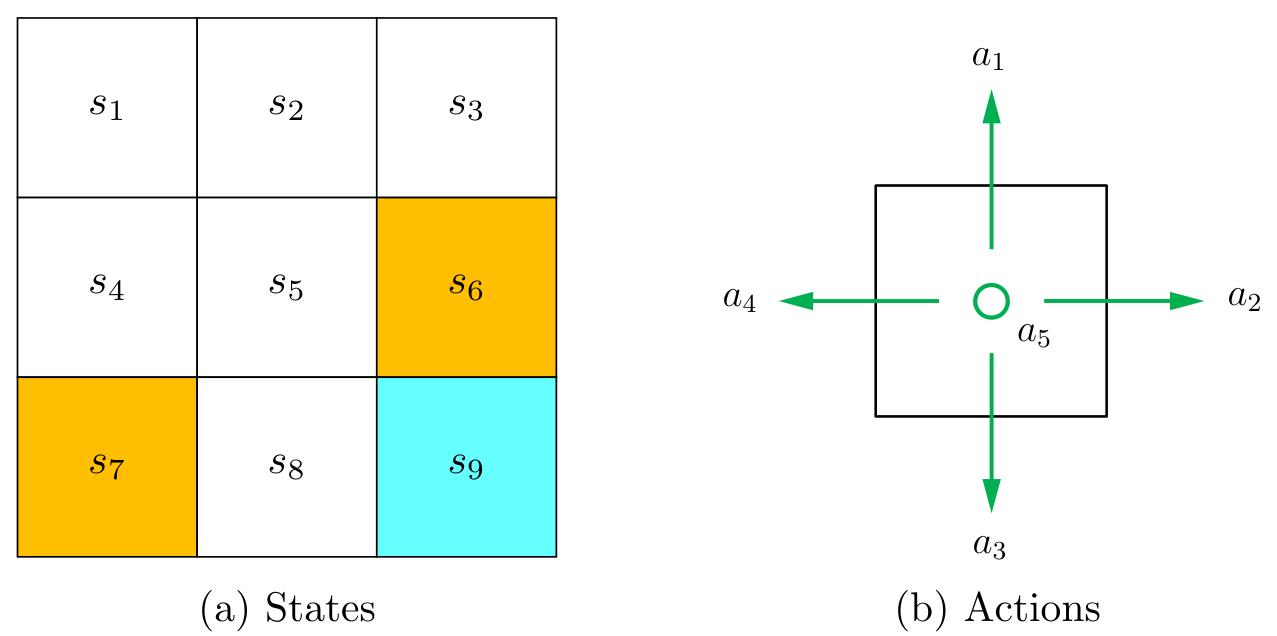
Figure 1.3: Illustrations of the state and action concepts. (a) There are nine states
1.3 State transition
When taking an action, the agent may move from one state to another. Such a process is called state transition. 状态转移
For example, if the agent is in state
We next examine two important examples.
What is the next state when the agent attempts to go beyond the boundary, for example, taking action
What is the next state when the agent attempts to enter a forbidden cell, for example, taking action
Which scenario should we consider? The answer depends on the physical environment. In this book, we consider the first scenario where the forbidden cells are accessible, although stepping into them may get punished. This scenario is more general and interesting. Moreover, since we are considering a simulation task, we can define the state transition process however we prefer. In real- world applications, the state transition process is determined by real- world dynamics.
The state transition process is defined for each state and its associated actions. This process can be described by a table as shown in Table 1.1. In this table, each row corresponds to a state, and each column corresponds to an action. Each cell indicates the next state to transition to after the agent takes an action at the corresponding state.
| a1 (upward) | a2 (rightward) | a3 (downward) | a4 (leftward) | a5 (still) | |
|---|---|---|---|---|---|
| s1 | s1 | s2 | s4 | s1 | s1 |
| s2 | s2 | s3 | s5 | s1 | s2 |
| s3 | s3 | s3 | s6 | s2 | s3 |
| s4 | s1 | s5 | s7 | s4 | s4 |
| s5 | s2 | s6 | s8 | s4 | s5 |
| s6 | s3 | s6 | s9 | s5 | s6 |
| s7 | s4 | s8 | s7 | s7 | s7 |
| s8 | s5 | s9 | s8 | s7 | s8 |
| s9 | s6 | s9 | s9 | s8 | s9 |
| Table 1.1: A tabular representation of the state transition process. Each cell indicates the next state to transition to after the agent takes an action at a state. |
Mathematically, the state transition process can be described by conditional probabilities. 条件概率 For example, for
which indicates that, when taking
Although it is intuitive, the tabular representation is only able to describe deterministic state transitions. In general, state transitions can be stochastic and must be described by conditional probability distributions. For instance, when random wind gusts are applied across the grid, if taking action
1.4 Policy
策略 A policy tells the agent which actions to take at every state.
Intuitively, policies can be depicted as arrows (see Figure 1.4 (a)). Following a policy, the agent can generate a trajectory starting from an initial state (see Figure 1.4 (b)).
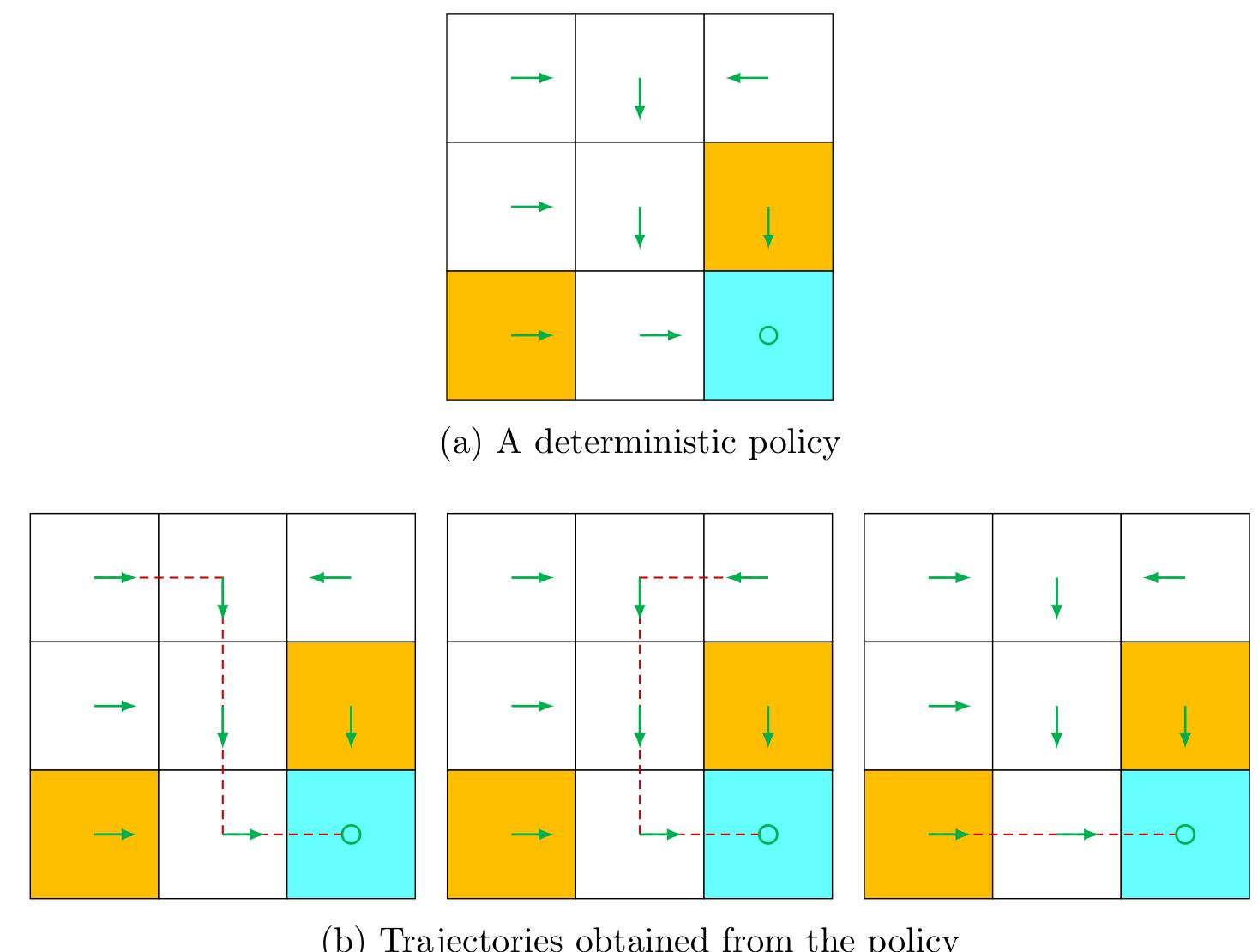
Figure 1.4: A policy represented by arrows and some trajectories obtained by starting from different initial states.
Mathematically, policies can be described by conditional probabilities . Denote the policy in Figure 1.4 as
在此策略下
which indicates that the probability of taking action
The above policy is deterministic. Policies may be stochastic in general. For example, the policy shown in Figure 1.5 is stochastic: in state
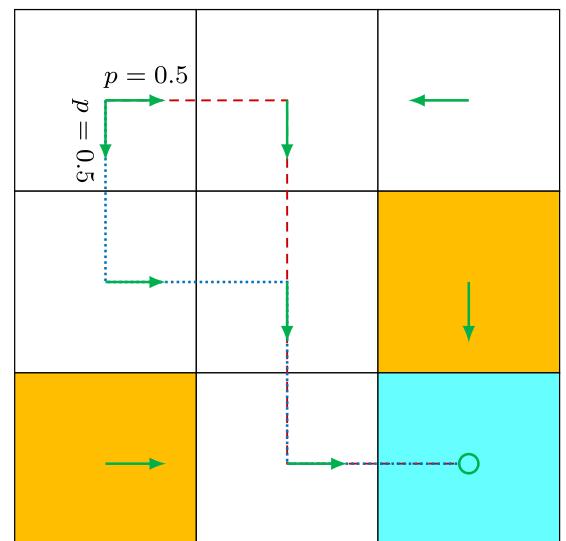
Figure 1.5: A stochastic policy. In state
Policies represented by conditional probabilities can be stored as tables. For example, Table 1.2 represents the stochastic policy depicted in Figure 1.5. The entry in the ith row and jth column is the probability of taking the jth action at the ith state. Such a representation is called a tabular representation. We will introduce another way to represent policies as parameterized functions in Chapter 8.
| a1 (upward) | a2 (rightward) | a3 (downward) | a4 (leftward ) | a5 (still) | |
|---|---|---|---|---|---|
| s1 | 0 | 0.5 | 0.5 | 0 | 0 |
| s2 | 0 | 0 | 1 | 0 | 0 |
| s3 | 0 | 0 | 0 | 1 | 0 |
| s4 | 0 | 1 | 0 | 0 | 0 |
| s5 | 0 | 0 | 1 | 0 | 0 |
| s6 | 0 | 0 | 1 | 0 | 0 |
| s7 | 0 | 1 | 0 | 0 | 0 |
| s8 | 0 | 1 | 0 | 0 | 0 |
| s9 | 0 | 0 | 0 | 0 | 1 |
Table 1.2: A tabular representation of a policy. Each entry indicates the probability of taking an action at a state.
1.5 Reward
奖励 Reward is one of the most unique concepts in reinforcement learning.
After executing an action at a state, the agent obtains a reward, denoted as
Its value can be a positive or negative real number or zero. Different rewards have different impacts on the policy that the agent would eventually learn. Generally speaking, with a positive reward, we encourage the agent to take the corresponding action. With a negative reward, we discourage the agent from taking that action. In the grid world example, the rewards are designed as follows:
In the grid world example, the rewards are designed as follows:.
If the agent attempts to exit the boundary, let
Special attention should be given to the target state
A reward can be interpreted as a human- machine interface, with which we can guide the agent to behave as we expect. For example, with the rewards designed above, we can expect that the agent tends to avoid exiting the boundary or stepping into the forbidden cells. Designing appropriate rewards is an important step in reinforcement learning. This step is, however, nontrivial for complex tasks since it may require the user to understand the given problem well. Nevertheless, it may still be much easier than solving the problem with other approaches that require a professional background or a deep understanding of the given problem.
The process of getting a reward after executing an action can be intuitively represented as a table, as shown in Table 1.3. Each row of the table corresponds to a state, and each column corresponds to an action. The value in each cell of the table indicates the reward that can be obtained by taking an action at a state.
One question that beginners may ask is as follows: if given the table of rewards, can we find good policies by simply selecting the actions with the greatest rewards? The answer is no. That is because these rewards are immediate rewards that can be obtained after taking an action. To determine a good policy, we must consider the total reward obtained in the long run (see Section 1.6 for more information). An action with the greatest immediate reward may not lead to the greatest total reward.
Although intuitive, the tabular representation is only able to describe deterministic reward processes. A more general approach is to use conditional probabilities
| a1 (upward) | a2 (rightward) | a3 (downward) | a4 (leftward) | a5 (still) | |
|---|---|---|---|---|---|
| s1 | 0 | 0 | 0 | ||
| s2 | 0 | 0 | 0 | 0 | |
| s3 | 0 | 0 | |||
| s4 | 0 | 0 | 0 | ||
| s5 | 0 | 0 | 0 | 0 | |
| s6 | 0 | rtarget | 0 | ||
| s7 | 0 | 0 | |||
| s8 | 0 | rtarget | 0 | ||
| s9 | 0 | rtarget |
Table 1.3: A tabular representation of the process of obtaining rewards. Here, the process is deterministic. Each cell indicates how much reward can be obtained after the agent takes an action at a given state.
This indicates that, when taking
1.6 Trajectories, returns, and episodes
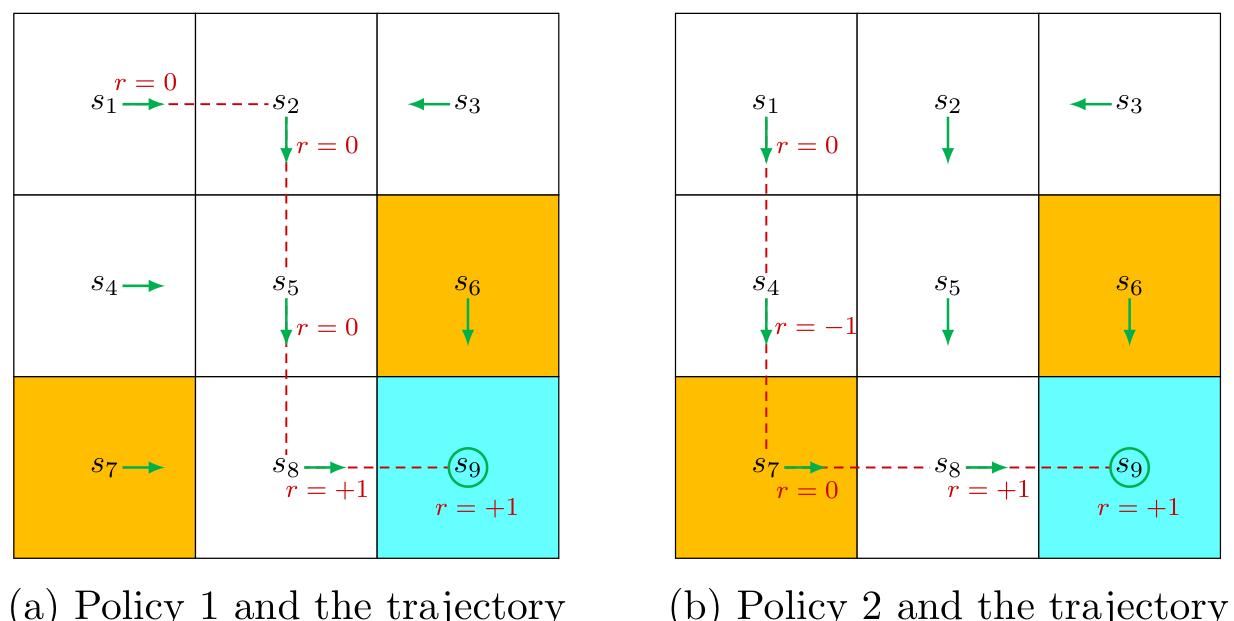
Figure 1.6: Trajectories obtained by following two policies. The trajectories are indicated by red dashed lines.
A trajectory is a state-action-reward chain. 轨迹是状态-动作-奖励的链
For example, given the policy shown in Figure 1.6 (a), the agent can move along a trajectory as follows:
The return of this trajectory is defined as the sum of all the rewards collected along the trajectory:
Returns are also called total rewards or cumulative rewards. 累计奖励
Returns can be used to evaluate policies. For example, we can evaluate the two policies in Figure 1.6 by comparing their returns. In particular, starting from
The corresponding return is
The returns in (1.1) and (1.2) indicate that the left policy is better than the right one since its return is greater. This mathematical conclusion is consistent with the intuition that the right policy is worse since it passes through a forbidden cell.
A return consists of an immediate reward and future rewards. Here, the immediate reward is the reward obtained after taking an action at the initial state; the future rewards refer to the rewards obtained after leaving the initial state. It is possible that the immediate reward is negative while the future reward is positive. Thus, which actions to take should be determined by the return (i.e., the total reward) rather than the immediate reward to avoid short- sighted decisions.
The return in (1.1) is defined for a finite- length trajectory.
Return can also be defined for infinitely long trajectories.
For example, the trajectory in Figure 1.6 stops after reaching
The direct sum of the rewards along this trajectory is which unfortunately diverges.
Therefore, we must introduce the discounted return concept for infinitely long trajectories. In particular, the discounted return is the sum of the discounted rewards: 折扣奖励
where
The introduction of the discount rate is useful for the following reasons.
First, it removes the stop criterion and allows for infinitely long trajectories.
Second, the discount rate can be used to adjust the emphasis placed on near- or far- future rewards.
In particular,
- if
is close to 0, then the agent places more emphasis on rewards obtained in the near future. The resulting policy would be short- sighted. - If
is close to 1, then the agent places more emphasis on the far future rewards. The resulting policy is far-sighted and dares to take risks of obtaining negative rewards in the near future. These points will be demonstrated in Section 3.5.
One important notion that was not explicitly mentioned in the above discussion is the episode. When interacting with the environment by following a policy, the agent may stop at some terminal states. The resulting trajectory is called an episode (or a trial). If the environment or policy is stochastic, we obtain different episodes when starting from the same state. However, if everything is deterministic, we always obtain the same episode when starting from the same state.
- An episode is usually assumed to be a finite trajectory. Tasks with episodes are called episodic tasks.
- However, some tasks may have no terminal states, meaning that the process of interacting with the environment will never end. Such tasks are called continuing tasks.
In fact, we can treat episodic and continuing tasks in a unified mathematical manner by converting episodic tasks to continuing ones. To do that, we need well define the process after the agent reaches the terminal state. Specifically, after reaching the terminal state in an episodic task, the agent can continue taking actions in the following two ways.
First, if we treat the terminal state as a special state, we can specifically design its action space or state transition so that the agent stays in this state forever. Such states are called absorbing states, meaning that the agent never leaves a state once reached. For example, for the target state
Second, if we treat the terminal state as a normal state, we can simply set its action space to the same as the other states, and the agent may leave the state and come back again. Since a positive reward of
In this book, we consider the second scenario where the target state is treated as a normal state whose action space is
1.7 Markov decision processes
The previous sections of this chapter illustrated some fundamental concepts in reinforcement learning through examples. This section presents these concepts in a more formal way under the framework of Markov decision processes (MDPs).
An MDP is a general framework for describing stochastic dynamical systems. The key ingredients of an MDP are listed below.
- State space: the set of all states, denoted as
. - Action space: a set of actions, denoted as
, associated with each state . - Reward set: a set of rewards, denoted as
, associated with each state-action pair .
- State transition probability: In state
, when taking action , the probability of transitioning to state is . It holds that for any .
在状态下,采取动作 转移到状态 的概率 - Reward probability: In state
, when taking action , the probability of obtaining reward is . It holds that for any .
在状态下,采取动作 获得奖励 的概率
在策略
where
Here,
One may have heard about the Markov processes (MPs). What is the difference between an MDP and an MP? The answer is that, once the policy in an MDP is fixed, the MDP degenerates into an MP. For example, the grid world example in Figure 1.7 can be abstracted as a Markov process. In the literature on stochastic processes, a Markov process is also called a Markov chain if it is a discrete- time process and the number of states is finite or countable. In this book, the terms “Markov process” and “Markov chain” are used interchangeably when the context is clear. Moreover, this book mainly considers finite MDPs where the numbers of states and actions are finite. This is the simplest case that should be fully understood.
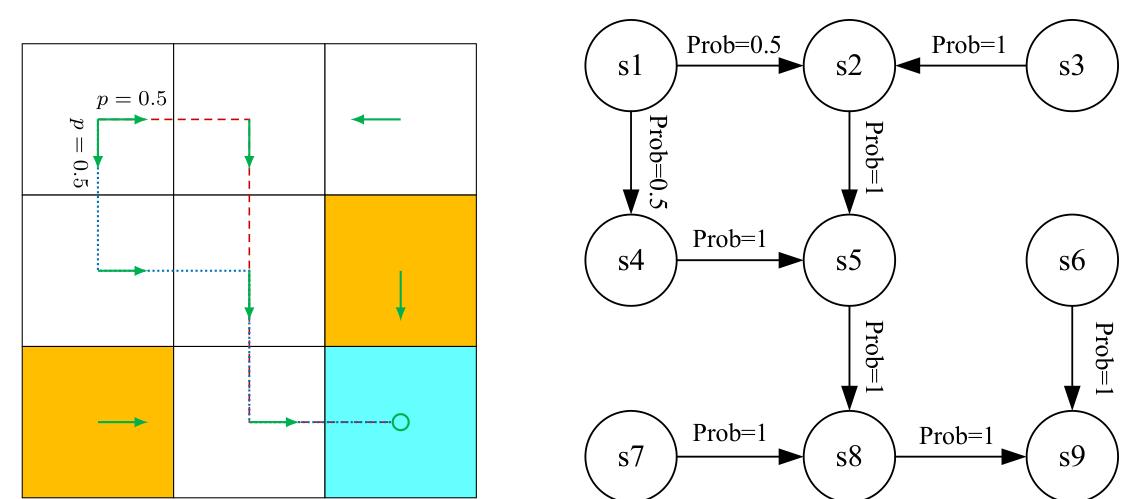
Figure 1.7: Abstraction of the grid world example as a Markov process. Here, the circles represent states and the links with arrows represent state transitions.
Finally, reinforcement learning can be described as an agent- environment interaction process. The agent is a decision- maker that can sense its state, maintain policies, and execute actions. Everything outside of the agent is regarded as the environment. In the grid world examples, the agent and environment correspond to the robot and grid world, respectively. After the agent decides to take an action, the actuator executes such a decision. Then, the state of the agent would be changed and a reward can be obtained. By using interpreters, the agent can interpret the new state and the reward. Thus, a closed loop can be formed.
1.8 Summary
This chapter introduced the basic concepts that will be widely used in the remainder of the book. We used intuitive grid world examples to demonstrate these concepts and then formalized them in the framework of MDPs. For more information about MDPs, readers can see [1,2].
1.9 Q&A
Q: Can we set all the rewards as negative or positive? A: In this chapter, we mentioned that a positive reward would encourage the agent to take an action and that a negative reward would discourage the agent from taking the action. In fact, it is the relative reward values instead of the absolute values that determine encouragement or discouragement.
More specifically, we set
Q: Is the reward a function of the next state?
A: We mentioned that the reward