Deepseek-OCR
https://github.com/deepseek-ai/DeepSeek-OCR
- Transformers + PyTorch + FlashAttention 模式
- vLLM 模式
Deepseek-OCR API示例
Deepseek-OCR 配套工具
unknown
<|grounding|>Convert the document to markdown.
Describe this image in detail.
Locate <|ref|>eyes<|/ref|> in the image.
一、环境配置
1. CUDA 安装
bash
nvidia-smi
nvcc --version # 看是否有 cuda
# 如果无cuda 下载cuda
sudo apt update
sudo apt install nvidia-cuda-toolkit #注意此指令默认最新 13.0 的版本
# 11.8 版本下载地址 https://developer.nvidia.com/cuda-11-8-0-download-archive
# 如果有cuda(错误版本)
sudo apt-get --purge remove "cuda*" "nvidia-cuda*" "libcudart*" "libcublas*" "libcusolver*" "libcufft*" "libcurand*" "libcusparse*" "libnpp*" "libnvjitlink*" "libnvrtc*" "libnccl*" "libcudnn*" -y
sudo apt-get autoremove -y
sudo apt-get autoclean -y
## 去除残余路径
sudo rm -rf /usr/local/cuda*
sudo rm -rf /usr/lib/cuda*
sudo rm -rf /usr/include/cuda*
sudo rm -rf /usr/share/doc/nvidia-cuda*
sudo rm -f /usr/bin/nvcc
# 如果有cuda(正确版本) 但是未添加环境变量或希望切换系统cuda
which nvcc # 返回 cuda 编译器的路径
gedit .bashrc # 修改终端配置文件
export CUDA_HOME=/usr/local/cuda # 替换为 which nvcc返回的路径
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
source ~/.bashrc # 重新加载配置
2. Clone 仓库
Clone this repository and navigate to the DeepSeek-OCR folder
bash
#拉取官方仓库
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
3. Conda 环境创建
3.1 必要流程
bash
# 检查conda版本 或 是否有conda环境
conda --version
# 创建conda环境
conda create -n deepseek-ocr python=3.12.9 -y
# 激活特定conda环境
conda activate deepseek-ocr
# 下载好必要的库文件
pip install -r requirements.txt
transformers==4.46.3
tokenizers==0.20.3
PyMuPDF
img2pdf
einops
easydict
addict
Pillow
numpy
3.2 Pytorch 方式下载指令
bash
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==2.7.3 --no-build-isolation
3.3 VLLM 方式下载指令
首先下载 vllm -0.8.5 对应版本到本地文件夹中(下载地址 https://github.com/vllm-project/vllm/releases/tag/v0.8.5 )
然后下载到 conda 环境中:
bash
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl #vllm
unknown
pip install accelerate>=0.26.0
pip install bitsandbytes
二、模型文件下载
DeepSeek-OCR 模型文件较大,必须启用 LFS。
1. LFS 下载
bash
sudo apt update
# 安装 git-lfs,-y 无需手动确认
sudo apt install git-lfs -y
# 查看 git-lfs 版本
git lfs version
2. 模型文件下载与拉取
bash
#git clone https://huggingface.co/deepseek-ai/DeepSeek-OCR
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/DeepSeek-OCR
git lfs install
git lfs pull --include="*"
这些文件是通过 Git LFS 托管的,刚安装完 LFS,第一次拉取时会:
- Git 先拉下小文件(配置、代码等);
- 到大文件部分时转交 LFS;
- LFS 去 Hugging Face 服务器下载;
- 如果网络不稳定或被墙,就会一直停在 “Filtering content”。
三、Deepseek-OCR 配置
通用配置
PyTorch 调用方式
https://www.bilibili.com/video/BV1Vd1NBJEhA/
unknown
pip install accelerate>=0.26.0
pip install bitsandbytes
vLLM 调用方式
https://www.bilibili.com/video/BV1ju1jBHE6r/
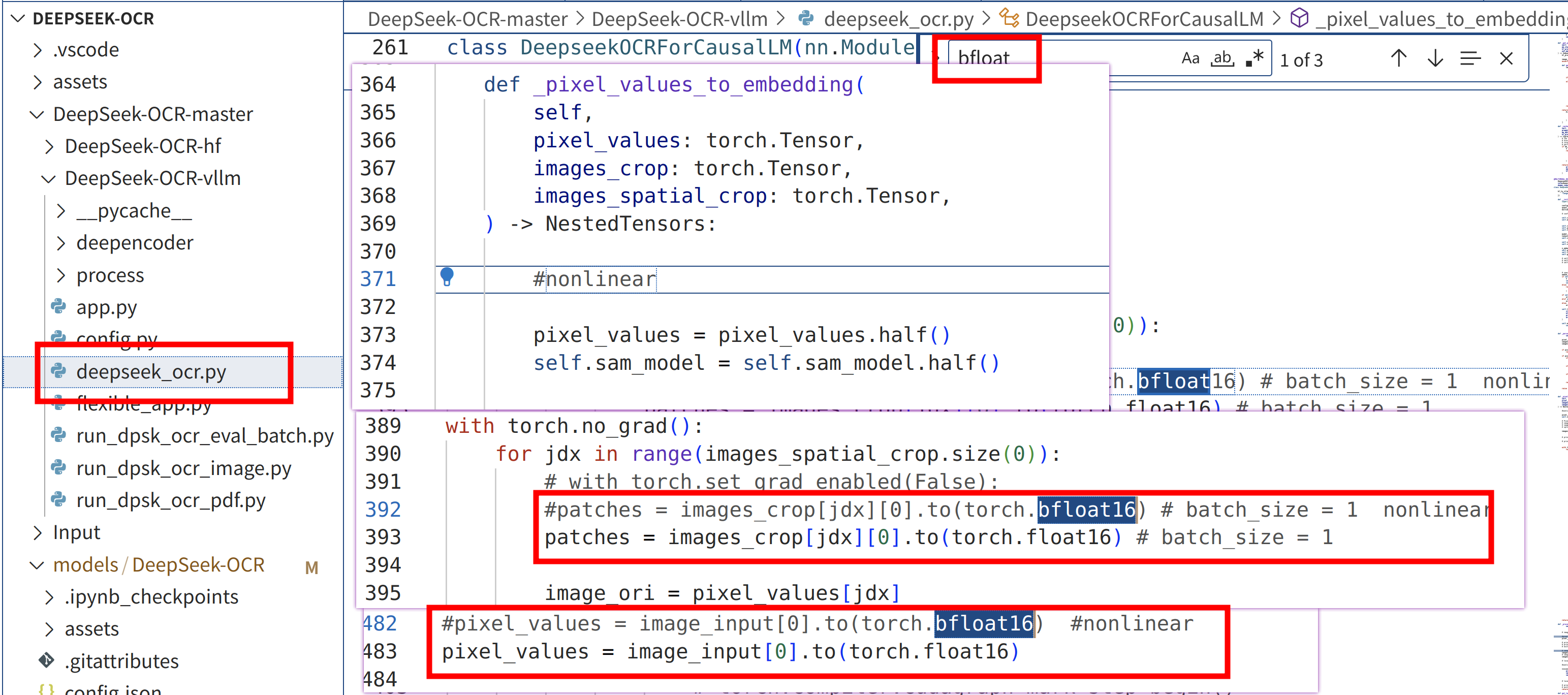
8GB 显存改动 (未完善)
OCR 识别结果
text
input_file = '/home/nonlinear/DeepSeek-OCR/Input/test.pdf' # 或 .png
output_path = '/home/nonlinear/DeepSeek-OCR/Output'
# 输出结果
output_path/
├── images/
│ └── 0.jpg # ocr识别的图片
│ ├── 1.jpg
│ ├── ...
├── result_with_boxes.jpg # ocr分块
└── result.md # 转换的md文件
unknown
python -m vllm.entrypoints.openai.api_server \
--model /home/nonlinear/DeepSeek-OCR/models/DeepSeek-OCR \
--host 0.0.0.0 \
--port 8000